By definition, supervised learning is generally used to classify data or make predictions, whereas unsupervised learning is generally used to understand relationships within datasets. Therefore, supervised learning is much more resource-intensive due to labelled data. Various examples of supervised learning have been given in the assigned reading, such as spam detection as part of an email firewall, distinguishing between conglomerate and non-profit novels, and spotify’s recommended songs model. These differences made me think of the notebook we did previously with the one we did today. In unsupervised learning, we do not have any training dataset which is the plus point for supervised learning and therefore, it is the best predictor.
Sinykin and Roland talks in: Against Conglomeration: Nonprofit Publishing and American Literature After 1908” about how ‘multiculturalism’ evolved in the world of literature. It was started by the government to include the diverse population that defined the new America; however, during the process of establishing the ‘multiculturalism’, things ended up being categorized in the form of specific titles and reputation given to the authors (African American/ Asian American/ Indian American) who had no specific goals to achieve such prejudiced and racist titles that created categories in the name of diversity. But is this really a multiculturalism? Aren’t we categorizing people according to their race and expecting them to create their work on their cultural basis? Non-profits did this because they had a gain of money, and it was the government who promoted this which got standardized due to the profit-gain. However, apart from all the downside, we can not deny that due to non-profits, chances were given to those who were considered outsiders (non-white people) in the field of literary.
We are experiencing a similar situation in the current period where all the non-profits are collecting data to improve society and create less discrimination. However, they are facing a lot of challenges in doing so. For example, Machine learnings (ML) algorithms are generated to pick candidates for hiring. In order to make unbiased decision, the algorithm has to be taught to not gender/race discriminate the candidate. According to supervised learning process, these algorithms would need the data on gender and race to align with the unbiasedness. Therefore, in reality, it is very hard to remove the gender and race-specified data as they are required to fight against the discrimination. However, most of the time it is misused at this certain place. As Ben Schmidt states in his article “the most important rule for thinking about artificial intelligence is that it’s deleterious effects are most likely in places where decision makers are perfectly happy to let changes in algorithms drive changes in society. Racial discrimination is the most obvious field where this happens”. Therefore, this is the most opportunistic area for the Feminist scholars to work on. I have provided a similar argument in the Notebook as well.
In conclusion, we can say that supervised learning is a really good feature of machine learning if used properly; or else, it can create many societal issues such as discrimination and racialization by categorizing things in groups.
Topic modeling is a machine learning technique that spontaneously analyzes the text data to determine the clustered words of a set of texts. In other words, this is called ‘unsupervised’ machine learning as it does not require a predefined list of tags or trained data that has already been classified by humans. Topic modelling helps to identify common themes of the texts. Text can have multiple perspectives that can cause the problem of being unable to address text at all its possible levels simultaneously. Topic modelling helps to achieve this goal.
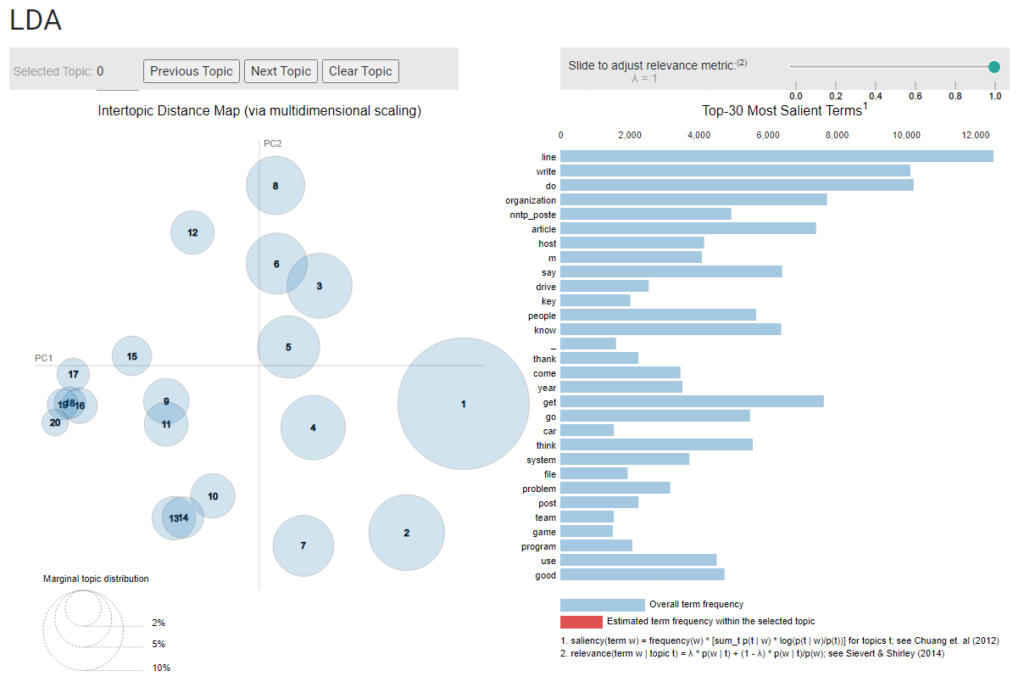
After reading various assigned articles, I can visualize both the advantages and the disadvantages of LDA topic models. There is comparison/similarity about LDA with market produce that was mentioned in Lisa Rhody’s article. But what I am wondering is – isn’t the produce at market a very simple concept compared to LDA. The size of topics reflects the estimation of how much each kind of topic (in poetry) is available. However, would it be unfair if the algorithm somehow misinterprets certain words (co-occurrence of words) with something else and hence, gathers false evaluation of the estimated topics? Though the authors reflect on this saying that LDA does a pretty good job with its method of discovery, there is still no sign for 100 percent accuracy. Therefore, this may lead to some loss of authenticity or loss of accuracy of theme evaluation.
I want to make some comparisons with what we learned in our previous readings. We worked on clustered algorithms which is also unsupervised machine learning similar to topic modelling. Whoever, while looking at the contrary side, typical clustering algorithms like K-means rely on distance measure between topics, but LDA topic model does not perform any distance measuring. This means that LDA lacks the ability to predict the relation of topics to one another and just performs a probability test. Matthew Jocker’s article also talks about similar thing where it is stated that “the manner in which the computer (or dear Hemingway) does the calculation is perhaps less elegant and involves a good degree of mathematical magic”. This tells us how the narrative feature/structure (for example, of poetry) is lost along with the relation between two topics while calculating just the probability of the topics/themes.
In conclusion, it will not be wrong to say that topic modeling is more of an “exploratory” data analyzer rather than “explanatory”. Topic modeling can reveal patterns and initiate questions, but it is less appropriate to test and confirm them.
Technologies of Speculation: The Limits of Knowledge in a Data-Driven Society — Sun-Ha Hong (NYU Press, 2020)
Starting from the question, “What counts as knowledge in our data-driven society?”Sun-Ha Hong argues that technologies of datafication are not only transforming the conditions for producing, accessing, wielding, and validating information—they are also articulating a new set of normative demands: that we, as liberal subjects, come to know our social/political world and ourselves within that world through these technologies, regardless of the technologies’ imperfections and contradictions.
Hong maintains that we are called on to live, reason, and act through ‘data-driven insights.” Confronted with technological systems of power and control so vast and complex that “transparency” becomes burdensome rather than empowering, the public becomes overwhelmed by surveillance dragnets and driven to speculation and paranoia. At the same time, provided with a surfeit of recursive data about our desires, habits, and even our bodies, we are encouraged to privilege machinic forms of intelligence and analysis over human experience and affect. In so doing, we’re rewarded for tailoring our behaviors to be compatible with the machines surrounding us—and thus compatible with the institutions behind the machines. For Hong, “datafication is turning bodies into facts: shaping human life, desire, and affect into calculable and predictable forms, and doing so, changing what counts as the truth about those bodies in the first place” (4).
Operating at the nexus of sociology of knowledge, history of science, and critical data studies, Technologies of Speculation grounds its examination into the epistemological consequences of datafication by focusing on two sites: the 2014 Snowden affair (revelations of mass-scale government surveillance) and automated self-tracking (e.g. Fitbit). Though these research sites seem distant at first glance, Hong uncovers remarkable commonalities between state surveillance on the one hand and self-surveillance on the other. In both, the process of turning bodies into facts results not in crystalline objectivity, but in troubling gaps and asymmetries: “If data expands the vistas of human action and judgement, it also obscures them, leaving human subjects to work ever harder to remain legible and legitimate to the machines whose judgment they cannot understand” (7).
So how does this often-philosophical investigation of data-driven, algorithmic intelligence and its discontents relate back to our realm of text analysis? We might start by considering how powerful regimes like the ‘intelligence community’ confront uncertainty when saturated in data. In Chapter 5, “Bodies into Facts,” Hong explores the fragile and improvisational techniques that are used to fabricate so-called “insights” out of massive reams of data and metadata. Attending to public discourse on post-9/11 counter-terrorism and surveillance, he argues that beneath the guise of objectivity, datafication is implemented through “inconsistent and locally specific strategies governing how uncertainties are selected and legitimated as predictive insights” (115). Hong specifies three techniques by which fabrications achieve knowledge status:
Subjunctivity: “As-if” reasoning, where a hypothetical or unproven situation is operationalized for decision-making (e.g., Acting to prevent the terrorist threat that could have happened; Acting as if you are being surveilled).
Interpassivity: Something or someone else knows or acts for the subject, in their stead. A kind of subjective outsourcing whereby one is not responsible for a statement/belief (e.g., a rumor heard elsewhere) yet that belief/statement—neither disavowed nor claimed as one’s own—nonetheless provides the basis for actions or opinions. But the other that knows and acts for the subject is not just other people—it van also be a machine.
Zero-Degree Risk: The dilemma of calculating risk out of uncountable streams of data with the goal of total de-risking: preventing a single outcome (e.g. a terrorist attack). Statistics, probabilities, and equations are invoked to mitigate fundamental, radical uncertainty and legitimate costly regimes of surveillance and control (NYPD counter-terrorism budget and the attacks that ‘might have been’).
Though Hong focuses explicitly on terrorist threats and state surveillance, we can consider how these techniques of fabrication may be operative in computational text analysis. For instance, “subjunctivity” undergirds many classificatory schemes. Cameron Blevins and Lincoln Mullen’s package for inferring gender based on historical first name data works as if gender is a binary, a limitation they explore in depth within their article introducing the method (Blevins and Mullen). More fundamentally, tokenization processes generally require us to treat texts as if they lack punctuation or line-breaks. We must make locally specific choices as to whether words that are capitalized should be treated differently, which will then reshape the predictive insights we can make about frequency, association, topics, and sentiments. Similarly, the process of training a model might be an instance of “interpassivity” when that model is working on a training set that has not been annotated by our own hand. In turn, we encounter issues analogous to risk calculation when weighing questions of model fit and overfit.
But given the scant references to “text” qua text in Technologies of Speculation, it seemed to me that the monograph provided few, if any specific, new avenues of research or new methodologies we might employ in text analysis. Instead, Sun-Ha Hong asks us to step back and consider the moral dimensions of the sort of knowledge production in which we are involved. He writes in the acknowledgements that “this book is about values: the subservience of human values to the rationality of technology and capital and, specifically, the transmutation of knowledge from a human virtue to raw material for predictive control” (201). From this standpoint, methods that may have once appeared value-neutral become morally charged. The study of authorship and style through quantification—sentence length, punctuation, vocabulary size—submits a humanist endeavor to machinic rationality. It isolates “style” from meaning and social/political context, reducing a lifetime of thought to numeric signature, eschewing genealogies of interpretation and contestation among human readers while at times obscuring its own algorithmic innerworkings. Consider another case: binary classification using TensorFlow neural networks. Let’s say we wanted to take a large corpus of prose paragraphs and sort it into “prose poems” and “not prose poems.” We have training data: a whole bunch of prose poetry ranging from Baudelaire to Rosmarie Waldrop, intermixed with paragraphs from magazine pieces, novels, and other texts. But after we train the model, we cannot ask it why or how it chose to call one paragraph a poem and another not. Its reasoning is obscured, and in Hong’s framework, the knowledge of what constitutes poetry has been transmuted into “raw material for predictive control,” where before, for better or worse, it was thought “a virtue.” Perhaps this is all beside the point, but at a time when humanism can feel under threat, where we are hailed by machine intelligence to shape our behaviors according to the whims of the algorithm, the stakes of computational text analysis can feel heightened, even dangerous, after reading Hong’s book.
Works Cited
Blevins, Cameron, and Lincoln Mullen. “Jane, John … Leslie? A Historical Method for Algorithmic Gender Prediction.” Digital Humanities Quarterly, vol. 009, no. 3, Dec. 2015.
Hong, Sun-ha. Technologies of Speculation: The Limits of Knowledge in a Data-Driven Society. New York University Press, 2020.
I have read the first three chapters of Artificial Unintelligence. Broussard discusses the issues in applying computer technology to every aspect of our lives and the limitations of artificial intelligence. She gives the name “Technochauvinism” to the idea that computers could always solve all human problems. The example she writes about AlphaGo is pretty straightforward, telling us computers work very well or “intelligently” in a highly structured system, just like the “Smart Games Format.” However, AI or computers can lead to algorithmic injustice and discrimination due to the data or orders the creators feed them.
Chun discusses the concepts of “correlation,” “homophily,” and “network science” in her article “Queerying Homophily” in Pattern Discrimination. I also found her explanation in this interview, Discriminating Data: Wendy Chun in Conversation with Lisa Nakamura amazing; she explained how correlation is treated by eugenics and big data as a future predictor, which actually turns out to close the future. I understand what she means by “closing the future” is closing alternatives for the future that are not predictable by the current and past data. I understand homophily is something amplified by people sharing their previous knowledge, experience, behavior, preferences, etc. Echo chambers and bubbles are generated by this homophily data collection and analysis method, further reinforcing the segregation in our society.
I am trying to make a connection here between the above two readings and the Topic Modeling articles for this week. My question for topic modeling will be how to avoid oversimplifying the context, figurative language, and nuance in discovering the topics. If an alternative reading is possible, how can this kind of representation be included in deciding the topics? For example, while the Latent Dirichlet Allocation (LDA) method could give you the percentage of possibility in similarities for topics, is it possible to address something like the impossible topics or the farthest options, or any other kinds of correlations?
The readings for this week remind me of a conversation my friend and I had a long time ago. We think math is a very romantic field because it starts with an agreement between two people that 1 + 1 = 2. If we don’t have a mutual agreement like this, the world will change accordingly. For example, I read that someone was trying to train ChatGPT that 1 + 1 = 3, and the machine will eventually accept it after a bit of struggle. To summarize my post, I believe we need to revisit concepts like “homophily” and “correlation” to keep space for agreement and mutual understanding, going beyond the aim of finding superficial similarities.
The ones who are invited or planning to be in the buffet must have the idea of what is served on the menu. The background knowledge that is what I am referring to. The one perhaps is more important than the computational process or even the decision making process of how many latent topics are waiting to be discovered within a seemingly large pool of documents aka corpus. The magic is fascinating but overwhelming if the magician can not communicate with the audience. In the case of topic modeling, the magic is the machine with computational ability that does not have the ability to express on its own(not sentient!!!). There is a role for a magician, an expert to make the magic audience enchanting, putting context to the result.
Let me provide an example. A while back, I conducted an experiment of topic modeling on the DigitalNZ archive of historical newspapers. The result is the following interactive illustration of topics. I decided to uncover 20 topics that are more prevalent during the New Zealand Wars in the 1800s.
The interactive visualization is available in the following URL
I played the role of the magician to demystify the result and present it to a broader audience who is not a historian by no means. I used intuition to and lent the superpower of Google to support my intuition to derive the bowl that represents the topic. Below is the result I came up with. I could not produce all the 20 topics I was hoping to find.
Representing news about Port Nicholson during the war in Wellington 1839
Table 2: some of the topics and explanations from gensim Mallet model
After working long hours on this project, although I am super delighted that I have produced an interactive visualization of the mallet model which is hard to produce, there is always a feeling of disappointment that I did not have the knowledge of the historian. A historian with special knowledge of New Zealand’s history might have judged better.
Attending buffet without the knowledge of the menu is like sailing a boat without the compass but isn’t it what the distant reading is? A calculated leap of faith.
Locating the beautiful, picturesque, sublime and majestic: spatially analysing the application of aesthetic terminology in descriptions of the English Lake District
Authors/Project Team: Christopher Donaldson – Lancaster University Ian N. Gregory – Lancaster University Joanna E. Taylor – University of Manchester
WHAT IT IS
An investigation of the geographies associated with the use of a set of aesthetic terms (“beautiful,” “picturesque,” “sublime,” and “majestic”) in writing about the English Lake District, a region in the northwest of England with a long and prestigious history of representation in English-language travel writing and landscape description, notably in the 18th and 19th centuries. The Lake District has been a particular focus within the field of spatial humanities for well over a decade, motivated in part by “an awareness of the braided nature of the region’s socio-spatial and cultural histories; and an understanding of this rural, touristic landscape as a repeatedly rewritten and imaginatively overdetermined space” (Cooper and Gregory 90).
Focusing on the four aforementioned terms, which exemplify a new language of landscape appreciation emerging in late 18th century British letters, Donaldson and his co-authors intend to “demonstrate what a geographically orientated interpretation of aesthetic diction can reveal about the ways regions like the Lake District were perceived in the past” (44).
Through this case study, the authors introduce the method of “geographical text analysis,” which they locate at the nexus of aesthetics, physical geography, and literary study. The project combines corpus linguistics with geographic information systems (GIS) in a novel fashion.
Primary Data Source:
Corpus of Lake District Writing, 1622-1900 (Github)
The corpus contains 80 manually digitized texts totaling over 1.5-million word tokens.
Natural language processing (NLP) techniques were used to identify place names and assign these names geographic coordinates—a method called “geoparsing.” But the project members also went beyond what was possible at the time with out-of-the-box NLP libraries and geoparser tools in order to deeply annotate the texts, linking place-name variants and differentiating a wide range of topographical features. As such, the corpus “forms a challenging testbed for geographical text analysis methods” (Rayson et al.).
What you’d need to know to conduct “geographical text analysis”:
Step 1: Geoparsing
If your corpus is not already annotated, you will need to “geoparse”—convert place-names into geographic identifiers.
Geoparsing involves two stages of NLP:
Named Entity Recognition (NER) – a method for automatically extracting placenames from text data
Named Entity Disambiguation (NED) – a method for linking the extracted and identified terms with existing knowledge, enabling cross-referencing and connections to metadata such as geo-spatial information.
The authors go about identifying the specific geographies associated with “beautiful,” “picturesque,” “sublime,” and “majestic” by noting when those terms appear alongside placenames. Thus, the authors develop a dataset of placename co-occurrences or “PNCs” extracted from their corpus. They then assess the frequency of co-occurrence to determine the statistical significance of the association between a given place and one of the aesthetic terms.
With the statistically significant PNCs identified, the authors use geoparsing tools to assign latitude/longitude (mappable) coordinates to each PNC. This enables researchers to analyse the spatial distribution of PNCs through GIS software such as ArcGIS, creating standard dot maps as well as density-smoothed maps. They also use Kulldorf’s Spatial Scan Statistic (traditionally an epidemiological statistic) to identify clusters.
With sophisticated GIS, they can map the spatial coordinates of the PNCs onto topographical and geological datasets, enabling a rich understanding of how places described as “majestic,” for example, map onto different elevations or different geological formations.
Digital terrain models (DTMs) or Digital Elevation Models (DEM) are vector and raster maps that can be imported into GIS tools if they are not already included. National geological surveys provide geology data in the form of GIS line and polygons that can be matched with PNC spatial metadata.
Donaldson et al.’s geographic analysis yields some striking findings on how the four aesthetic terms are applied to the Lake District landscape, which the authors summarize thusly:
As we have seen, whereas beautiful and, more especially, picturesque are often associated with geographical features set within, and framed by, their environment, majestic is more typically associated with features that rise above or extend beyond their surroundings. Sublime, true to Burke’s influential conception of the term, stands apart from these other terms in being associated with formations that are massed together in ways that make them difficult to differentiate […] The distinctive geographies associated with the terms beautiful and picturesque, on the one hand, and majestic and sublime, on the other, confirm that the authors of the works in our corpus were, as a whole, relatively discerning about the ways they used aesthetic terminology.
(Donaldson et al. 59)
References Cited:
Cooper, David, and Ian N. Gregory. “Mapping the English Lake District: A Literary GIS.” Transactions of the Institute of British Geographers, vol. 36, no. 1, 2011, pp. 89–108.
Donaldson, Christopher, et al. “Locating the Beautiful, Picturesque, Sublime and Majestic: Spatially Analysing the Application of Aesthetic Terminology in Descriptions of the English Lake District.” Journal of Historical Geography, vol. 56, Apr. 2017, pp. 43–60. ScienceDirect, https://doi.org/10.1016/j.jhg.2017.01.006.
Rayson, Paul, et al. “A Deeply Annotated Testbed for Geographical Text Analysis: The Corpus of Lake District Writing.” Proceedings of the 1st ACM SIGSPATIAL Workshop on Geospatial Humanities, Association for Computing Machinery, 2017, pp. 9–15. ACM Digital Library, https://doi.org/10.1145/3149858.3149865.
Can AI accurately determine gender when we conduct different kinds of studies? Can AI help in improving gender and racial equality? Allen Jiang’s article is very clear and compelling, showing us an approach to detecting gender with a machine-learning model with Twitter data. I appreciate Jiang’s methodology and explanation but still doubt the initial questions “Can you guess the gender better than a machine” and “What are business cases for classifying gender.” From my perspective, for example, pregnancy is not a gender-specific topic, and optimizing advertising costs could be achieved by non-binary customers’ gender detection. These questions reflect the definitions of gender I constructed derived from readings in week 2, Language and Gender by Penelope Eckert and Sally McConnell-Ginet, and We Should All Be Feminists by Adichie, to name a few. Sex is undoubtedly a different concept compared with gender. Applying a spectrum of gender in a scalar structure would challenge Jiang’s model, particularly in terms of data organization.
Specifically, Jiang primarily selects Twitter accounts belonging to famous people. In the data collecting and cleaning process, how could Jiang avoid the “celebrity effect?” I could think of methods like improving data diversity. And I am also very confused why Jiang included the data of followers. Is it possible that followers could be a feature impacting gender detection or a confounding variable? I previously raised the question about the significance of repetition in experiments to reduce error effects, which assumes a single correct result as the goal. This article reminds me of cross-validation’s importance in training models’ performances in different scenarios. The key question here I propose is to reduce the dependence on a single model designed based on one dataset with specific features.
The Gendered Language in Teacher Reviews focuses on a more diverse group sharing the same occupation, “teacher.” Upon revisiting the process, I discovered that he writes, “Gender was auto-assigned using Lincoln Mullen’s gender package. There are plenty of mistakes–probably one in sixty people are tagged with the wrong gender because they’re a man named ‘Ashley,’ or something.” The data source of Lincoln Mullen’s package is “names and dates of birth, using either the Social Security Administration’s data set of first names by year of birth or Census Bureau data from 1789 to 1940.” (https://lincolnmullen.com/blog/gender-package-now-on-cran/) Unfortunately, Ben Schmidt is no longer maintaining the teach reviews site, but updating this data visualization remains crucial, as the association between names and gender conventions is constantly changing. Using data from the 1940s to train a model for detecting gender in contemporary society may not yield ideal results.
I continued to read two articles to help me think about the question bias in AI. One is an interview Dr. Alex Hanna received about her work at Distributed AI Research Institute on AI technology and AI bias and constraints. I recommend this interview, especially for her answers to the question on independent AI research and purposes not funded by tech companies.(https://www.sir.advancedleadership.harvard.edu/articles/understanding-gender-and-racial-bias-in-ai)
There is also another super interesting but quite dangerous reading named Natural Selection Favors AIs over Humans (https://arxiv.org/abs/2303.16200)
The author Dan Hendrycks is the director of the Center for AI Safety. He discussed the natural selection and the Darwinian logic applied to artificial agents. In such large-scale computational studies and models, if biased natural selection is also incorporated, would the consequences be unbearable for us as humans? If there is natural selection within AI, where does the human position be?
“How we do things with words: Analyzing text as social and cultural data” (Nguyen, Dong, Liakata, DeDeo, Eisenstein, Mimno, Tromble, Winters) asks us to consider the “Background Concept” —the messy complicated nuanced region of knowledge related to your area of interest— and the “Systemized Concept”—the boiled down quantifiable expression of that tangle that can be used to slice through your data for specific insight. In other words, to use digital text analysis effectively you must chip away at a great stone of knowledge until you have an arrowhead that will hit a small target. They make the point, of course, that how you hone this language becomes more difficult the more nuanced your subject matter. Spam, they say is a bit easier to chunk out into neat categories—offering a finite goal and measurably predictable tendencies.
Discussions of gender, on the other had, are quite the opposite. We get into trouble when we imagine that there is a single answer to most questions of human experience. Compare any two people and you get a different perspective, no matter what they may appear to have in common. Two siblings from the same family will have different insight, different struggles, different relationships within the rest of the family. Two women living in seemingly the same society will have different perspectives and experiences. And yet there has emerged a pattern of treatment towards women as a whole that is undeniable, despite uncovering the faulty reporting and interpretation of earlier scientific studies that exaggerated biological differences between the sexes (Eckert, Penelope, McConnell-Ginet). So undeniable is this pattern of treatment that a chapter entitled Introduction to Gender includes a list of adjectives traditionally attributed to each gender—ex. weak (f) vs. strong (m)—and anticipates it being familiar to readers.
As conducive to creating a “Systemized Concept” as this list may be, it ignores a myriad of influences on our understanding of every manner of our identities. When these same authors later insist on inserting what feels like a footnote that accidentally wandered into the text to acknowledge the white centered approach to their delineation of gender norms, it becomes very clear that their list of descriptors, so readily assumed as familiar, come with a great many caveats. Ethnicity, geography, and class are considerably large influences on how we express our gender, never mind the cultures expressed in every community circle we participate in—starting with our families. How then do we quantify gender expression in a reliable way? Is that a valid query, or does this reinforce gender norms due to rigid definitions of gender expression to query data?
Ahmed, in Living Feminist Life, invites us to confront internalized sexist assumptions on a daily basis. You first must, of course, teach yourself to be aware of them, as they’ve likely hidden themselves among all other reasonable cultural practices due to sheer ubiquity. This is an ongoing personal practice, but, as Ahmed argues, the big banner conversations must happen, but the changing of culture one interaction at a time is important.
This can prove more difficult than it seems, when we consider the human desire to make things digestible and manageable. Systems that we are familiar with can be hard to discern. Feminist advocates pointing to larger number of women speakers at global multi stakeholder conferences on the governance of the internet as a sign of progress (A History of Feminist Engagement with Development and Digital Technologies | Association for Progressive Communications. ) is a prime example. By choosing to assume that women will always support women and not be guided by other cultural, political, and ecomonic influences that shape their perspectives, it’s as though the authors of failed to question their own internalized assumptions about what motivates women as a whole.
So where does that leave scholars who are left to to try and comb out the shifting expressions of interconnected influences on their data come up with a “systemized concept?” This, in the end, reinforces the idea that technology used to investigate culturally complex subjects should be used as a tool to ask questions formulated in a finite context. Technology would be most effective as a probe to gather intel, but not, in this case, as the synthesizer.
This is a Post.Instructors often post announcements, assignments, and discussion questions for for students to comment. Some instructors have students post assignments. Posts are listed on the “Posts” page with the newest at the top.
PostComments are turned on by default(see Home for information on Comments).
Add/Remove a password from this post from the Post Editor > Visibility > Edit > Password Protected.
Add/Edit/Delete a post from Dashboard > Posts
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: