DirectHERS is a project that I was part of for the course DH Methodology and Practice. As a team, we build a text encoding project to represent Women Directors. I was in charge of building the search engine and was a part of the Dev team with Gemma for the project. When looking at possibilities for search engine creation, we considered three main routes:
1) Building a search engine with vanilla Javascript and Ajax which would be running within the limited capacity of GitHub pages. Although this option seemed feasible, the downside was the latency of information processing as the team would not be able to use a dedicated virtual machine (VM) in the cloud, hence causing the crawler to be slow at indexing and showing results. This solution would have also required optimization and code refactoring to enhance its performance.
2) Incorporating a basic search within GitHub pages in the knowledge that this would be limited to keywords search only but could grant a functional engine that could produce the desired output.
3) Creating a search engine within Tableau and leveraging Tableau Public’s resources that would later be embedded into our GitHub page. This solution seemed very palatable as it would meet the requirements for minimal, but efficient, computing.
Further to various attempts, the team would settle for a hybrid option, which also ended up being the most integrable solution for our website. We indeed used JavaScript but instead of allowing the crawler to dynamically crawl through XML files, we decided to build a common structure for our directors. This is basically a long structured xml file with tags that are relevant to all the directors. We later ingest the files directly with JavaScript to make them searchable. This uniformity enhances the query search runtime significantly. Since our sources are not changing dynamically, we do not need a dynamic crawler like a traditional search engine(for instance Google). Also, to finetune the runtime further, we have used a dictionary-based approach(key, value) where the key is the XML tags for the directors and the value is the associated information contained in the tag. The solution is great for cross-director search and can be used as a unique pedagogical tool to research the directors.
ChatGPT is a sophisticated computational model of natural language processing that is capable of producing coherent and semantically meaningful text through incremental word addition. This is accomplished by scanning and locating every occurrence of the text in question from an extensive corpus of human-authored text.Afterward, the system generates a ranked list of potential subsequent words, accompanied by their corresponding probabilities. The fascinating thing is that when we ask ChatGPT with a prompt like “Compose an Essay”, all it does is ask, “Given the text so far, what should the next word be?” over and over again, and then it adds a word one after another. However, if the model uses the highest-ranked words all the time, the essay it will produce will not be creative. The system utilizes a “temperature” parameter to decide how often lower-ranked probable words will be used. “Temperature” is one of the tunable parameters of the model, ranging from 0 to 1, where 0 produces the flattest essay with no creativity and 1 is the most creative.
The foundation of neural networks is numerical. Therefore, in order to utilize neural networks for textual analysis, it is necessary to establish a method for numerical representation of the text. This concept is fundamental to ChatGPT, which employs an embedding to attempt to represent the entities as a set of numbers. To create this kind of embedding, we must examine vast quantities of text to determine how similar the contexts in which various words appear are. Word embedding discovery requires beginning with a trainable job using words, such as word prediction. For instance, to solve “the ___ cat” problem, let’s say among the 50000 most common words used in English, “the” is 914 and “cat” (with a space before it) is 3542. Then the input is {914, 3542}. Output should be a list of approximately 50,000 numbers representing the probabilities for each of the potential “fill-in” terms. By intercepting the embedded layer, the neural network reaches its conclusion about which terms are appropriate.
Human language and the cognitive processes involved in its production have always appeared to be the pinnacle of complexity. However, ChatGPT has shown that a completely artificial neural network with a large number of connecting nodes resembling connected neurons in the brain can generate human language with amazing fidelity. The fundamental reason is that language is fundamentally simpler than it appears, and ChatGPT effectively captures the essence of human language and the underlying reasoning. In addition, ChatGPT’s training has “implicitly discovered” whatever linguistic (and cognitive) patterns make this possible.
Syntax of language and parse trees of language are two well-known examples of what can be considered “laws of language,” and there are (relatively) clear grammatical norms for how words of various types can be combined, such as nouns may have adjectives before them and verbs after them, but two nouns usually can’t be immediately next to each other. ChatGPT has no explicit “knowledge” of such principles, but through its training, it implicitly “discovers” and subsequently applies them. The most crucial information presented here is that a neural net can be taught to generate “grammatically correct” sequences, and there are several methods to deal with sequences in neural nets, including the use of transformer networks, which is what ChatGPT accomplishes. Like Aristotle, who “discovered syllogistic logic” by studying many instances of rhetoric, ChatGPT is projected to do the same by studying vast quantities of online literature with its 175B parameters.
Part of the Debates In the Digital Humanities series edited by Matt Gold and Lauren Klein, The Digital Black Atlantic gathers a wide group of experts in Africana studies from across the globe to consider the intersection of digital humanities and the study of African diasporas from a post-colonial perspective. Using Paul Gilroy’s foundational 1993 concept as a way to approach the long history of “the interstices of Blackness and technology” in order to work towards “a recognizable language and vocabulary . . . that spans the breadth of interdisciplinary scholarship in digital studies and digital humanities—including disciplines as varied as literary studies, history, library and information science, musicology, and communications,” editors Roopika Risam and Kelly Baker Josephs take “the Black Atlantic” in its broadest global sense as method and “object of study” (x). As such, the volume offers a helpful counterpart to questions raised by Feminist Text Analysis, including the interchange between theory and practice, even as its ultimate impact goes well beyond a feminist application. Acknowledging that this is a reductive reading, then, this book review will suggest how would-be feminist-text-analysis practitioners might find useful theoretical and practical examples in this important collection.
Grouped into four sections following Risam’s and Josephs’ Introduction—Memory, Crossings, Relations, Becomings—the twenty essays provide a range of methodologies and disciplinary areas from which to learn. Several focus on soundscapes and music, others on mapping and data visualizations—including video representations and immersive 3D simulations, still others emphasize the need for qualitative analysis in the construction of digital knowledges and for mindfulness of community applications and engagement. While all the pieces have something to offer feminist digital humanists, I will focus on three or four that are particularly suggestive in relation to the questions and challenges of Feminist Text Analysis raised by our course.
Amy E. Earhart’s “An Editorial Turn: Reviving Print and Digital Editing of Black-Authored Literary Texts,” emphasizes the need to engage both print and digital media in the project of textual recovery of a minoritized group’s writings. The essay’s focus on the limits of facsimile editions, particularly when texts and authors were under particular pressure to accommodate resistant reception, reminds us of the multiple mediations and lives of a single work and the importance of reconstructing their contexts for an understanding of the text’s potential intervention into socio-political conditions. Using two examples of information lost in productions of the facsimile series, the Collected Black Women’s Narratives, Earhart notes how the desire for consistency, similarity, or put another way, homophilia, “conceals the ways that the materiality of the texts indicates differences in authorial authority, notions of radicalness, and even difference in the gaze on the Black female body” (34) in works by Susie King Taylor and Louisa Picquet. She argues that a well-edited digital edition has the potential to allow “materials to be presented more fully because it does not face the space or economic constraints of print publication” including attention to color images, covers and frontispieces, as well as prefaces written by white male editors and publishers. Her final plea for making “careful editing a long overdue priority” particularly resonates for the recovery of Black female-authored texts that make up the bulk of her surprising examples of neglected works by or unremarked interventions in the texts of such celebrated writers as Zora Neale Hurston, Nella Larsen, and Toni Morrison, including the renaming of the titles of Passing and Paradise respectively.
In “Austin Clarke’s Digital Crossings,” Paul Barrett demonstrates how “the productive acts of translation required to move between the digital and the textual and that are inherent in the digital interpretive act” (85) demand that we recognize both the promise and the limits of literary textual analysis tools like topic modeling when approaching authors like Clarke whose works exemplify the “acts of crossing” inherent in the Black Atlantic diasporic imaginary. Revealing how “[t]hese acts of crossing . . . run counter to the intuition of topic modelling, which attempts to identify the thematic structure of a corpus and isolate themes from one another to make them readily identifiable” (86), Barrett provides a table of Topic Proportions and Topical Keywords that underline “the incommensurability between Clarke’s aesthetics of crossing and topic modeling algorithms” (88). Rather than marking this endeavor as a “failure of method” Barrett uses it to identify the need for a “methodology of digital humanities research that emerges our of an engagement with Black Atlantic politics and textuality” (86), the need for a new set of questions, or “a need to conceive of the method differently” (88)—a self-described “reflexive approach to topic modeling” (88) which feminist text analysis at its best also advocates. Like Earhart’s, Barrett’s close analysis indicates the consistent imbrication of race and gender identities in their textual examples: Barrett’s investigation into Clarke’s nation language and Creolization finds that “speaking in nation language is a decidedly masculine pursuit in Clarke’s work” (89). Barrett ends by summarizing “three important dimensions of what might be conceived of as a critical digital humanities” one we might consider equally urgent for a feminist digital practice of recovery and analysis: “rendering a text worldly, resisting the positivism of computational logic by working to represent the presence of absence, and recognizing that the act of ‘making it digital’ is actually a re-formation of the text into something new” (90-91).
Anne Donlon’s “Black Atlantic Networks in the Archives and the Limits of Finding Aids as Data” offers important comparisons between metadata applied at different times and to different archives that problematize looking for cultural network histories for specific groups. “People researching minoritized subjects not overtly represented in collections have learned to read between the lines and against the grain to find their subjects” (168); similarly “digital methods and tools might offer increased access and possibilities for understanding archival collections in new ways, but they do not do so inherently” (169). Donlon proceeds to chart her own experiences working with collections in the Manuscripts, Archives, and Rare Book Library at Emory as a case study for how to revise one’s expectations and outcomes when confronted with disparities and lacunae in the archive. She explains, “Rather than try to read these networks as representative of cultural and historical networks, I came to read them on a more meta level, as representative of how collections are described and arranged” (177). Suggesting that “Perhaps, then, we could develop methods to read data from finding aids against the grain . . . to identify bias . . . [t] imagine new structures to describe collections” (177), Donlon extends Barrett’s “presence of absence” [op cit] to the bibliographical textual corpus itself, seeing it as well as a site for reproduction of power imbalances and the reification of prior canon-building.
Finally, Kaiama L. Glover’s and Alex Gil’s exchange, “On the Interpretation of Digital Caribbean Dreams,” offers a welcome corrective to a familiar tension between the “theory” brought by literary critics to the texts and the “tools” provided by digital designers and makers or, as Barrett puts it, “the difficult dialogue between the texts we study and the digital tools we use” (90). Barrett’s suggestion that “dwelling in the space between the incommensurability of the text and the digital tools suggests the possibility of a worldly digital humanities practice that eschews traditional forms of humanities and humanism” (90), gains traction in Gil’s emphasis on deploying minimal computing for his and Glover’s joint project. Rather than a division of labor in which the “dreams of the humanist too easily . . . end . . . up piped into existing visualization frameworks or . . . some D3 templates . . . in [this] case, the interpreters made the work interesting to themselves by exploiting the fortuitous intersection between cultural analytics and knowledge architectures” (231). By engaging “interpreters” and “dreamers” as equals rather than as “implementers” (232) and “auteurs” (231) and by resisting ready-made tools in favor of a slower but ultimately more streamlined “infrastructure, workflow, and pursestring” (231), Gil and Glover show another dimension and set of rewards for self-reflexive approaches to digital humanities projects. Or as Glover puts it, “it involved . . . getting me to see that there is no magic in my PC, that anything we were able to make would involve knowledge, transparency, ethics, error, and labor” (228). Ultimately, it is the acknowledgement of those conditions that offers the best hope for a truly feminist textual analysis.
Coda on the relative virtues of the print and digital editions:
Functionality—the Manifold edition allows annotations to be seen and shared, highlighting etc. including by our program colleagues and classmates (Majel Peters!), and easy access to links to other sites and references.
The print copy is a pleasure to read, with quality paper, legible lay-out, well-designed space, & attractive typography. It also keeps its extradiagetical materials easily at hand, with endnotes and bibliography at end of each essay. However, it has no searchable index, unlike the digital edition.
It should be said that the cover & opening pages and section divisions are designed for print but retained in the digital edition leading to some moments of static and illogical design. For example, the cover’s suggestive and striking iridescent bronze lettering only comes alive with a light source or manual use and ceases to function in digital form.
Title: Digging into Early Colonial Mexico (DECM) Historical Gazetteer
What it is:
A searchable digital geographic dictionary of 16th-17th-century Mexican toponyms, their present-day place names, and geographical coordinates.
It includes a GIS dataset with shapefiles containing geographic information for early colonial administrative, ecclesiastical, and civic localities–from provinces, to dioceses, to villages–for interactive mapping.
It deploys, for its historical data, the 16th-century Relaciones Geogràficas de Nueva España compiled from 1579-1585 in Madrid, that was based on a 1577 questionnaire sent to civic sites in New Spain, as well as modern editions of the RG, related secondary studies, and similar compilations for the province of Yucatán.
How (well) it works:
I’ve been obsessed with this database and the larger project of which it is a part—“Digging Into Early Colonial Mexico”—since I discovered it in 2021. https://www.lancaster.ac.uk/digging-ecm/
It applies a range of computational techniques, including Text Mining, Geographic Information Systems, and Corpus Linguistics, to render newly usable an early exemplar of imperial technology, the printed administrative survey, that was compiled in the late 17th century into a multivolume, multimodal, multilingual work. Through semi-automated access, applied language technologies, and geospatial analysis, this early modern textual corpus and its several thousand pages become uniquely functional despite their resistance to easy translation into contemporary digital form.
It also exemplifies the interdisciplinary and inter-institutional possibilities of Digital Humanities, bringing together specialists from a number of research centers, universities, and academic disciplines to share knowledge and professional experience in new ways. And its acknowledgement of manual disambiguation as a necessary part of the process confirms the need for the slow, careful, historically and contextually aware analog-to-digital transformation foregrounded in current theories of feminist and post-colonial digital praxis.
What you’d need to have, know, or use:
Comprehensive primary sources in print pdf or digital editions.
Present-day cartographic, geographical, or toponymic databases: eg. GeoNames; National Geospatial-Intelligence Agency (NGA) place names database; Getty Thesaurus of Geographical Names. (see Murrieta-Flores 2023 for topographic and toponymic catalogues and databases specific to the colonial New Spain period.)
Adobe Acrobat or Google Drive (OCR conversion from PDF image format to machine-readable text/txt format)
Excel for shapefiles, tables, combined information (xy coordinates, notes, bibliographical references), and metadata.
ArcGIS or equivalent GIS Desktop tool for shapefiles: to join colonial toponyms to current place names for linguistic and spatial disambiguation (may require manual input and review) and to create layers.
Alternativesor additions in extreme cases:
Named Entity Recognition tool in (eg) Recogito (for extracting place names from modern, European, monolingual documents) with Natural Language Processing platform like Tagtog for model training.
ArcMap and Google Earth for advanced spatial disambiguation
Useful links:
For more on the making or potential applications of the DECM Historical Gazetteer:
Murrieta-Flores, P. (2023) The Creation of the Digging into Early Colonial Mexico Historical Gazetteer. Process, Methods, and Lessons Learnt. Figshare. 10.6084/m9.figshare.22310338
In a lecture on mass media, one of my undergraduate professors posited a question: “Does media shape culture, or does culture shape media?” As we would come to learn throughout the course, the answer wasn’t either but both.
The same is true for technology. In the series foreword for “Pattern Discrimination” by Apprich, et al., the authors quote Friedrich Kittler: “Media determine our situation.” In the series of articles that follows, authors address points in the continuum between technological determinism and social constructionism, while explicating issues ranging from homophily in network science to the politics of pattern recognition.
Throughout the Text Analysis course we’ve learned about various tools and methodologies. We’ve also been encouraged to think critically about data, its collection, and use. And while some of the dystopian futures presented in the series are more imaginative, some (especially regarding pattern bias) are present, here and now, affecting and shaping our lives.
In “Queerying Homophily” part of the series, Wendy Chun states: “It is critical that we realize that the gap between prediction and reality is the space for political action and agency.” There are also other spaces, at the personal and interpersonal-level where we can contribute to how society and technology are shaped, experienced, and lived. There are decisions made on every level of data collection, manipulation, and programming. There are also decisions we make in how we interact, petition, and talk about our workspaces, communities, and experiences.
This week, we were introduced to a basic TensorFlow template for creating a predictive model for text. The immediate possibilities were exciting; however, as the articles emphasize, excitement should be tempered by thought, action by caution, and seek “unusual collaborations that both respect and challenge methods and insights, across disciplines and institutions” as stated by Chun.
As tools proliferate, how we consider and utilize tools become more and more important. But perhaps more practically, how we view reality is of equal importance–the communities, language, and environment that surround us. Chun says: “Rather than similarity as breeding connection, we need to think, with Ahmed, through the generative power of discomfort.” Productive discomfort holds the potential of creating more human and inclusive patterns.
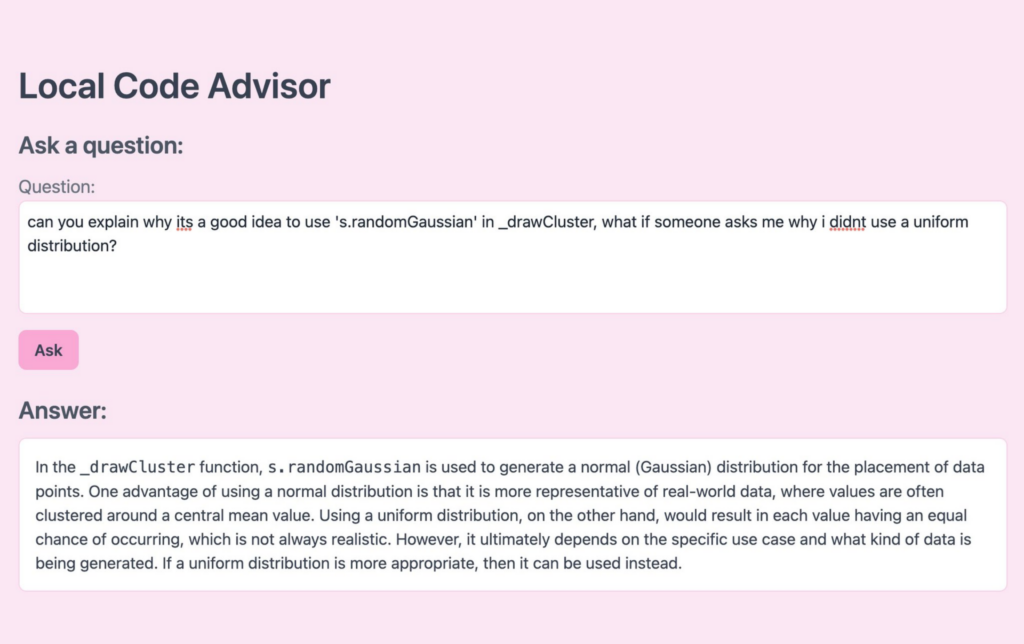
I created a simple web app, ASKode to help me code, I can ask the ChatGPT api a question about a small coding project and it will reply.
This open-source coding assistant aids in the process of learning and understanding code, making technology more approachable and accessible to beginners or to those with non-traditional backgrounds in coding. Such initiatives can help to disrupt the gender and racial disparities in the tech world and work towards a more diverse and inclusive tech community.
GITHUB LINK
ASKode’s development involved several steps, beginning with identifying the main requirements for the application: It should be able to answer coding-related questions based on the user’s local codebase.
Choosing the Technology Stack: The first step was choosing the technology stack for the project. As ASKode is a relatively simple app with no front-end, Node.js was chosen for its simplicity and compatibility with OpenAI’s GPT-3 API.
Setting up the OpenAI API: The next step was integrating GPT-3 into the application. This required obtaining an API key from OpenAI and setting it up to be used in the application.
Creating the Routes: Once the tech stack was in place and the API was set up, I created the necessary route in the application: the ‘ask’ route.
Developing the Answer Generation Process: The core of ASKode is the answer generation process. When a POST request is sent to the ‘ask’ route, the application extracts the question from the request body, and sends it to GPT-3. The model generates an answer based on the question and the content of the user’s local codebase, and this answer is then returned to the user.
Usage of ASKode
To use ASKode, follow these steps:
Clone the Repository: Clone the ASKode repository to your local machine.
Navigate to the Root Directory: Navigate to the root directory of the project in your command line.
Install the Dependencies: Run the command “npm install” to install the required dependencies.
Set up the API Key: Set the environment variable “API_KEY” to your OpenAI API key.
Set the Local Directory: Set the path to your local directory containing the code files by passing it as a command line argument when launching the app: npm run start -- /path/to/your/code.
Access the App: Go to the home page using http://127.0.0.1:5000/ or http://localhost:5000/.
Use the ‘ask’ Route: To use the app, send a POST request to the ‘ask’ route with a JSON body containing the question you want to ask, like so: { "question": "What is the purpose of this function?" }. The app will use GPT-3 to generate an answer to the question based on the code files in the specified directory
In Search of Zora/When Metadata Isn’t Enough: Rescuing the Experiences of Black Women Through Statistical Modeling
The authors searched for Alice Walker, who searched for Zora Neale Hurston, in an article that encompasses a generation of searching for cultural and gender visibility in the academic realm related to African American women’s authorship. The research method is based on both quantitative and qualitative analyses of 800,000 documents from the HathiTrust and JSTOR databases. Full article available here.
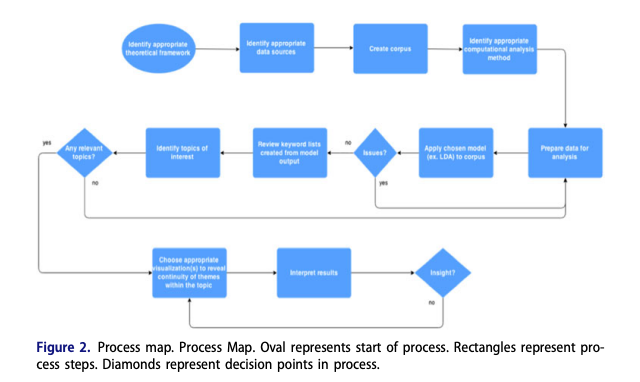
The research is based on Standpoint Theory, a critical conceptual framework intended to uncover knowledge for both reproducing and dismantling social inequality (Collins, 1990, 1998). This approach encompasses the search, recognition, rescue, and recovery (SeRRR), focusing on utilizing digital technologies to engage with intersectional identities. The authors establish three goals: identifying themes related to African American women using topic modeling, using the identified themes to recover unmarked documents, and visualizing the history of the recovery process.
They argue that social science would greatly benefit from digital technologies, such as big data, speech recognition, and other initiatives like The Orlando Project (2018), the Women Writers Project (Wernimont, 2013, p. 18), and the Schomburg Center’s digital library collection of African American Women Writers of the 19th Century (The New York Library, 1999). These projects challenge dominant power narratives by shedding light on new perspectives and dynamics of minority groups whose history has been overshadowed by the triumphalism of American capitalism, which presents an incomplete view of history from various perspectives.
They emphasized the importance of their quantitative approach over rich and descriptive qualitative research, aiming to create a repository of work that brings more visibility to a different side of the story, which is often uncovered through traditional approaches. They summarized their method in the image below.
The data collection used the string line (black OR “african american” OR negro) AND (wom?n OR female OR girl) within 800,000 documents from the HathiTrust and JSTOR databases spanning the years 1746 to 2014.
In terms of the analysis method, the authors employed a statistical topic modeling approach to identify documents discussing the experiences of Black women. They utilized a Latent Dirichlet Allocation (LDA) topic modeling technique (Blei, 2012), which clusters words based on the probability of their occurrence across documents using Bayesian probability. Each cluster is referred to as a topic.
They applied the SeRRR method to structure the search and the analysis. The first step is Search and Recognition of the results that are of interest to the Black woman content. In this step, they found 19,398 documents “authored by African Americans based on the metadata with known African American author names and/or phrases such as “African American” or “Negro” within subject headings”: 6,120 of these documents were within the HathiTrust database and 13,278 were within the JSTOR database.
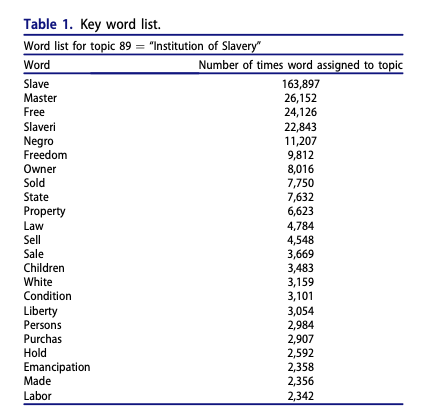
In the second step, the Rescue, they perform a topic analysis in the 19,398 documents. They ended up with 89 initial topics that were reviewed by 5 team members individually – as described in the table below. They used the method of “distant reading”, which can be interpreted as skimming the documents, but focusing on the titles.
They also developed a method called “intermediate reading” to reflect their reading process that ranges in between the traditional qualitative rich methods and the distant reading of topic modeling. The ultimate goal of this method is to validate the topics and support the quality of the results. The closed this step with a close reading of some full documents for several of these titles.
The third step is Recovery. They successfully rescued and recovered 150 documents previously unidentified related to Black women, including a poem written in 1920 called Race Pride by an African American woman named Lether Isbell.
In conclusion, this article successfully not only applied a research method, but they also contributed to enriching the research repo metadata and making new documents accessible to the academic community.
References
Nicole M. Brown, Ruby Mendenhall, Michael Black, Mark Van Moer, Karen Flynn, Malaika McKee, Assata Zerai, Ismini Lourentzou & ChengXiang Zhai (2019): In Search of Zora/When Metadata Isn’t Enough: Rescuing the Experiences of Black Women Through Statistical Modeling, Journal of Library Metadata, DOI: 10.1080/19386389.2019.1652967 To link to this article: https://doi.org/10.1080/19386389.2019.1652967
Note: this blog post about “How they did it is quite interesting” – here.
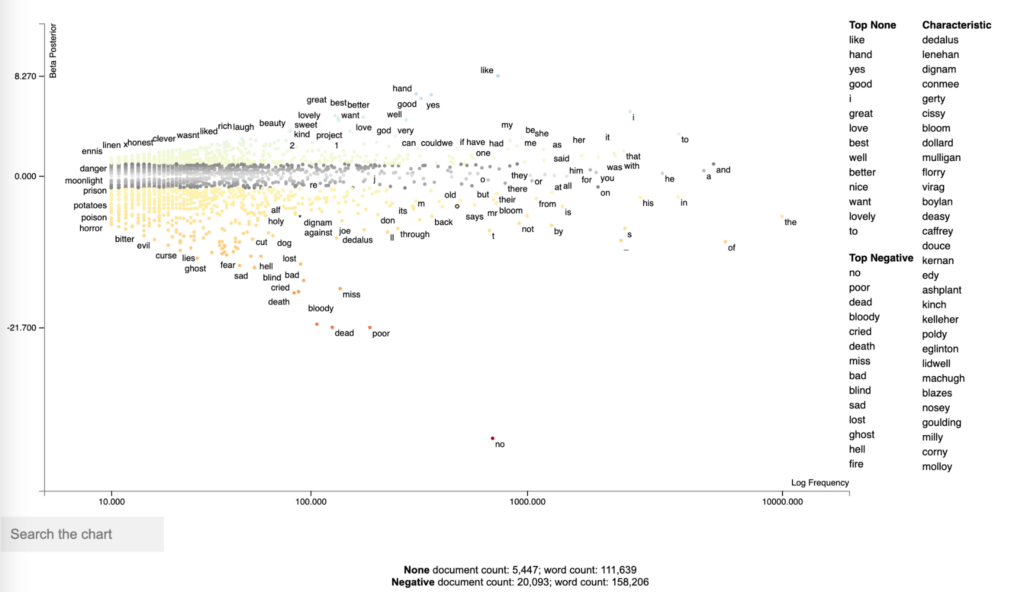
Inspired by the Book review Ulysses by Numbers by Eric Bulson, I have created a visualization of a sentiment analysis of the novel Ulysses. The visualization can be found here. The code for the analysis and the viz plotting is here.
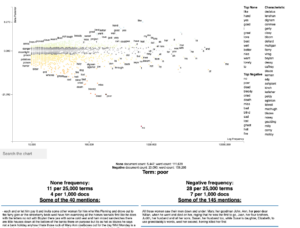
This visualization plots the words based on the frequency (X axis), and shows the top positive and negative words in a sidebar table with related characteristics (adjectives). The Y axis displays a score computed based on the sentiment categories (‘Positive’ and ‘Negative’).
The visualization is interactive, allowing us to search specific words, and retrieve the part of the text where the word occurs.
This HDTMT is intended to show how to run this analysis, and it’s divided into 5 sections, as follows:
Downloading and importing Ulysses data
Tokenizing data into sentences
Perform sentiment analysis
Plotting the visualization with scattertext
Deploying the html into github pages
Next steps and improvements
Downloading and importing Ulysses data
We start by importing “Requests”, the Python library that makes HTTP requests and will connect us to the Github repo where the Ulysses data is stored – here. The data comes from the Gutenberg EBook from August 1, 2008 [EBook #4300], updated on October 30, 2018.
Tokenizing data into sentences
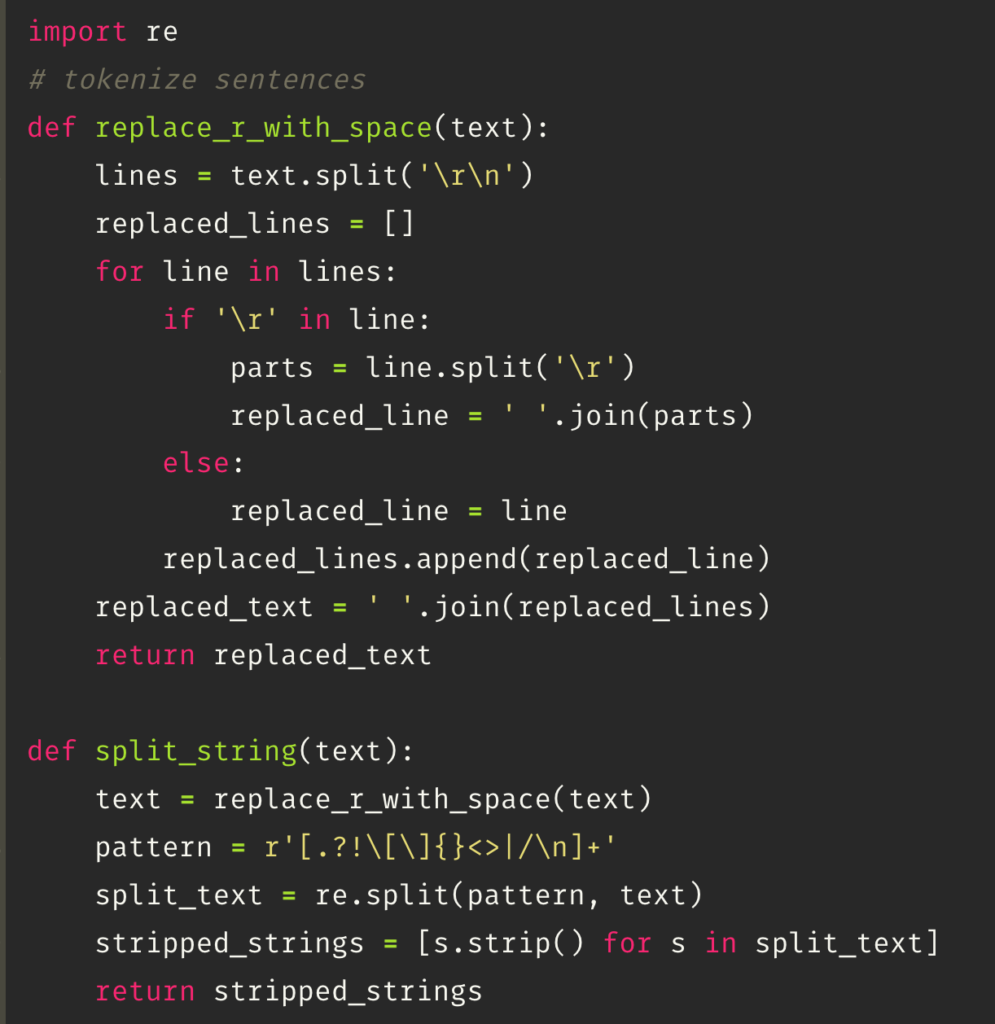
After importing the data, the next step involves cleaning and tokenizing the text into sentences. The data might contain noise such as line breaks (‘\n’) and misplaced line breaks (‘\r’). The function first joins the sentences with misplaced line breaks (‘\r’) to ensure they are connected properly. Then, it tokenizes the text into sentences by splitting the string using ‘\n’, line breaks, and punctuation marks as delimiters. This process ensures that the text is properly segmented into individual sentences for further analysis.
Perform sentiment analysis
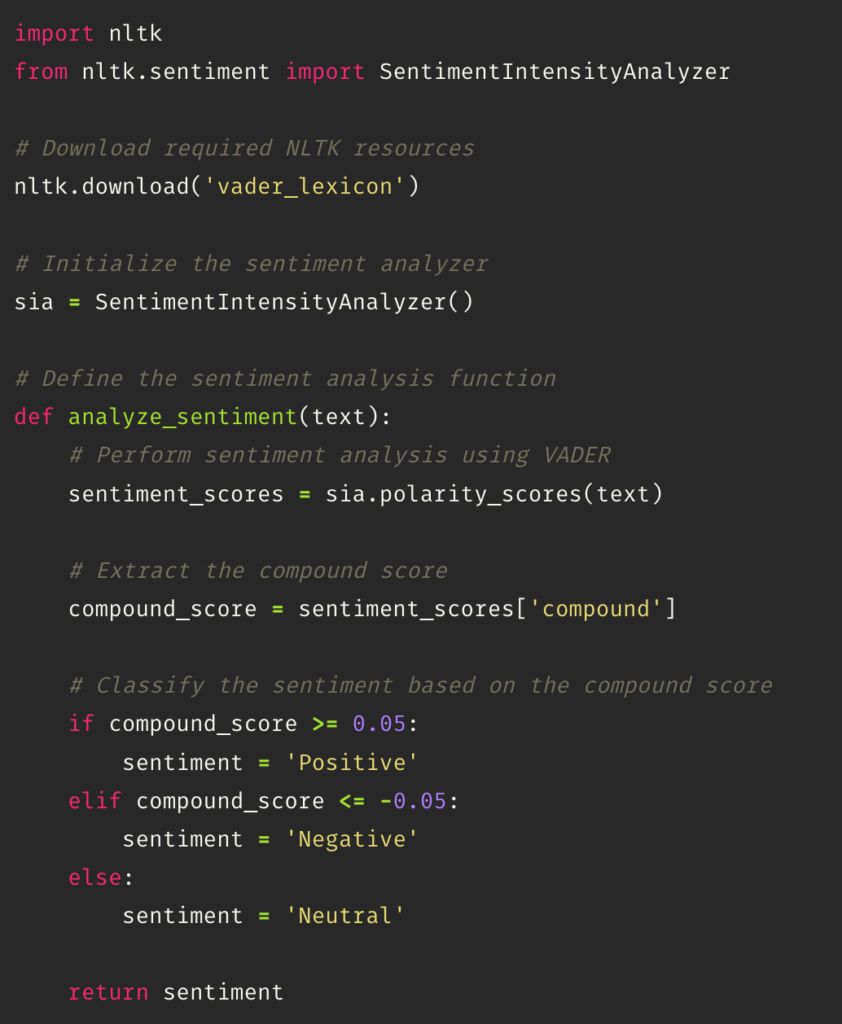
The next step is performing a sentiment analysis that classifies the text into positive, negative, and neutral tone. This task is performed using the class SentimentIntensityAnalyzer from the nltk.sentiment module in NLTK (Natural Language Toolkit).
The SentimentIntensityAnalyzer uses a lexicon-based approach to analyze the sentiment of text by calculating a compound score. The compound score is an aggregated sentiment score that combines the positive, negative, and neutral scores. The compound score ranges from -1 (extremely negative) to 1 (extremely positive). If the polarity is greater than 0.05 it can be considered positive; lower than 0.05 is negative, and the values in between are neutral.
Plotting the visualization with scattertext
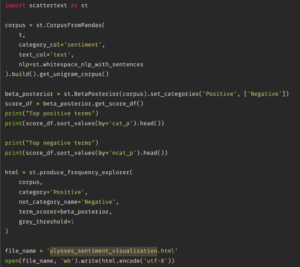
The next step is to import scattertext, a Python library that analyzes and creates an html file. The library receives a specific data type, which is a corpus that is created by using the CorpusFromPandas function. This takes a Pandas DataFrame (t) as input and specifies the category column (‘sentiment’) and text column (‘text’). The whitespace_nlp_with_sentences tokenizer is used for text processing. The corpus is then built, and the unigram corpus is extracted from it.
Then, it creates a BetaPosterior from the corpus to compute term scores based on the sentiment categories (‘Positive’ and ‘Negative’). Next, the get_score_df() method is called to get a DataFrame with the scores. The top positive and negative terms are printed based on the ‘cat_p’ (category posterior) and ‘ncat_p’ (non-category posterior) scores, respectively.
The produce_frequency_explorer function generates an interactive HTML visualization of the corpus. It specifies the corpus, the positive category, the name for the negative category, and the term_scorer as the BetaPosterior object. The grey_threshold parameter sets a threshold for terms to be displayed in gray if they have a score below it.
Finally, the resulting HTML visualization is saved to a file named ‘ulysses_sentiment_visualization.html’ using the open function.
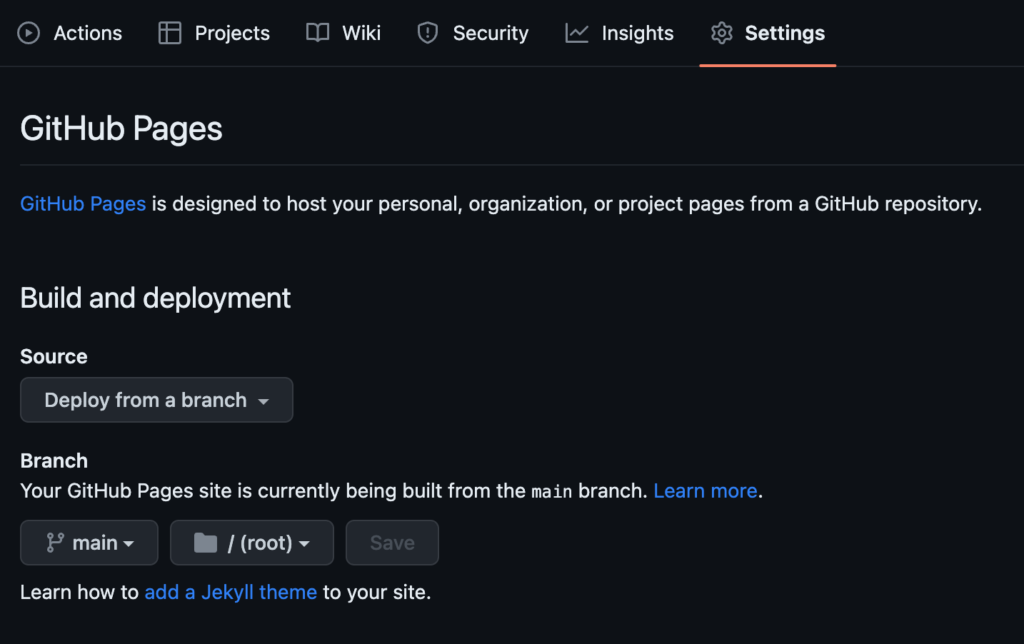
Deploying the html into Github pages
Lastly, we can deploy the html output from the scattertext visualization into a github page. We start by creating a Github repo. Then, uploading the html. Finally, going to settings and changing the deployment source – I’m using from branch, and main/ root in this case.
I’m pointing my Github pages into my alias, livia.work, but you can also use the Github service. This tutorial by professor Ellie Frymire has more details about how to perform the deployment step that can be helpful – here.
Bulson, Eric Jon. Ulysses by Numbers. Columbia University Press, 2020. cuny-gc.primo.exlibrisgroup.com, https://doi.org/10.7312/buls18604.
Summary: Eric Bulson employs a quantitative and computational approach to analyze the novel “Ulysses” by James Joyce. His objective is to gain insights into the novel’s structure and themes through the application of statistical methods. By examining the repetitions and variations of numerical patterns within the text, Bulson aims to uncover a deeper understanding of the novel.
My experience: It was an interesting, but challenging read for me. I did skim through the “Ulysses” by Joyce on multiple occasions, but I never fully immersed myself in its pages. Now, I’m feeling more open to giving it a try at some point in the future. Having that in mind, I mostly focused on understanding the method Bulson used to convey his message.
Eric Bulson is a professor of English at Claremont Graduate University. He got his PhD in English and Comparative Literature from Columbia University. His research interests goes on a range of subjects including Modernism, Critical Theory, Media Studies, World Literature, Visual Storytelling, and British and Anglophone Literature from 1850 to 2000.
Ulysses by Numbers highlights the presence of numeric patterns throughout “Ulysses,” asserting their role in shaping the novel’s structure, pace, and rhythmic flow of the plot. He suggests that Joyce’s deliberate use of numbers is purposeful, enabling him to transform the narrative of a single day into a substantial piece of artwork. Bulson explores the intentionality behind Joyce’s numerical choices, emphasizing how they contribute to the book’s richness and complexity. Additionally, the tone of Bulson’s analysis combines elements of playfulness and exploration, adding an engaging dimension to the discussion.
He emphasizes he will be focused on the “use numbers as a primary means for interpretation“, to make the point that a quantitative analysis is the missing point to compose a “close reading as a critical practice”. He proposed it as an additional method to the traditional literature review that focused on the text.
“Once you begin to see the numbers, then you are in a position to consider how it is a work of art, something made by a human being at a moment in history that continues to recede into the past. We’ll never get back to 1922, but by taking the measurements now, we are able to assemble a set of facts about its dimensions that can then be used to consider the singularity of Ulysses and help explain how it ended up one way and not another.”
Bulson recognizes that literature critique based on computational methods is still under development, and not quite popular yet. The utilization of computers in literary analysis is a relatively modern phenomenon, considering that the majority of such processes were conducted manually until a few centuries ago. The practice of using numbers to elaborate narratives was common until the 18th century in the work of Homer, Catullus, Dante, Shakespeare, and others. However, the rationalism of the upcoming area covered up this practice. Only in the 1960s did the search for symmetry and numerological analysis reemerged, culminating in the method of computational literary analysis (CLA).
Bulson explains that he differs from the usual approach to adapt the use of small numbers in his analysis. Firstly, his analysis is based on samples. It means that instead of analyzing the entire novel the author selects specific sections. Secondly, he recognizes that he applies basic statistical analysis. Despite the simplicity of his analysis, his goal is to make literature more visible.
In terms of sources, he goes deep into finding the sources of data he considered in this analysis:
“Measuring the length of the serial Ulysses, simple as it sounds, is not such a straightforward exercise. In the process of trying to figure this out, I considered three possibilities: the pages of typescript (sent by Joyce to Ezra Pound and distributed to Margaret Anderson, editor and publisher of the Little Review, in the United States), the pages of the fair copy manuscript (drafted by Joyce between 1918 and 1920 and sold to the lawyer and collector John Quinn), and the printed pages of the episodes in the Little Review (averaging sixty-four per issue).”
It’s interesting to notice how he illustrates his arguments with both handwriting and drawings with graphs and charts, which encompasses the idea of a craftwork mixed with technological visualizations.
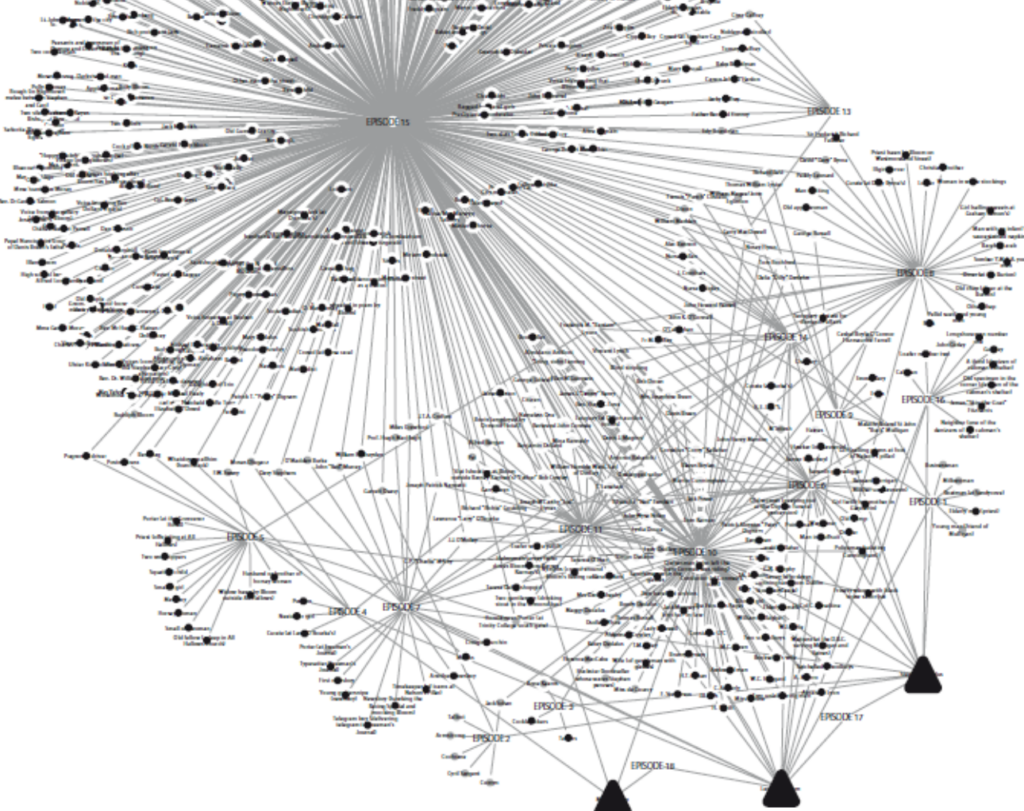
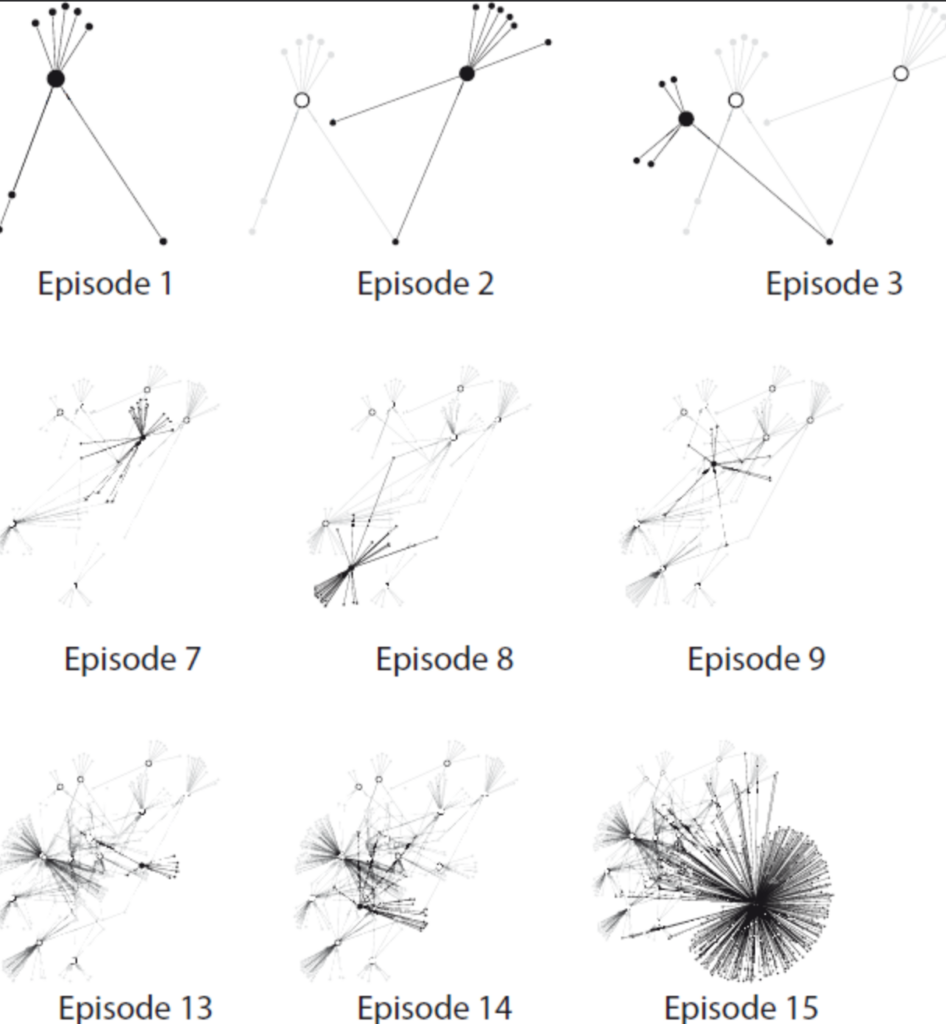
In terms of the novel’s structure, Bulson examines the presence of 2’s and 12’s, such as the address “12, rue de l’Odéon” and the year of publication (1922), among other recurring patterns. Additionally, he delves into the number of paragraphs and words in the text, and explores the connections between them. Through one particular analysis, he determines the level of connectivity among the chapters, identifying Chapter 15 as having the highest number of nodes and being the most connected to other chapters, which he refers to as an “Episode.” Chapter 15 consists of 38,020 words and 359 paragraphs. Another significant episode is Chapter 18, which contains the second-highest number of words (22,306) but is condensed into only 8 paragraphs. Chapter 11, on the other hand, has the second-highest number of paragraphs (376) and comprises 11,439 words.
Bulson also examines characters from a quantitative perspective, contrasting the relatively small number of character count in “Ulysses” with other epic works such as “The Odyssey” or “The Iliad.” He uses a visual representation of a network to enhance the understanding of the novel’s scale and structure – highlighting the crowded number of roles in episode 15.
“Episode 15 arrived with more than 445 total characters, 349 of them unique. If you remove the nodes and edges of episode 15 from the network, Ulysses gets a whole lot simpler . That unwieldy cluster of 592 total nodes whittles down to 235 (counting through episode 14). Not only is a Ulysses stripped of episode 15 significantly smaller: it corresponds with a radically different conception of character for the novel as a whole”.
Moving from the text meta analysis, the authors examine who read the 1922 printed book. Outside of Europe and North America, only Argentina and Australia. In the US, the book was most popular in the West Coast. In the following chapter, he tries to answer when Ulysses was written. He mentioned that the traditional answer is that Joyce began writing the novel in 1914 and finished it in 1921. However, he points out that this is such a simplistic answer. He argues about the nonlinearity of the written process, more fluid and organic, and less structured.
In the final chapter, the author goes back to the content analysis, bringing a reflection that could retreat himself “after reducing Ulysses to so many sums, ratios, totals, and percentages, it’s only fair to end with some reflection on the other inescapable truth that literary numbers bring: the miscounts”. He refers as “miscounts” any bias or issues in terms of data collection of analysis.However, he defends the method by saying that literary criticism is not a hard science, and imprecisions, vagueness and inaccuracy is actually part of the process. Also, theories based on small samples are popular in historical and social analysis, and his work should not be discredited because of that.
“Coming up against miscounts has taught me something else. Far from being an unwelcome element in the process, the miscounts are the expression of an imprecision, vagueness, and inaccuracy that belongs both to the literary object and to literary history. In saying that, you probably don’t need to be reminded that literary criticism is not a hard science with the empirical as its goal, and critics do not need to measure the value of their arguments against the catalogue of facts that they can, or cannot, collect.”
After reviewing the contribution of his perspective, he concludes that “readers might to bridge the gap, Ulysses will remain a work in progress, a novel left behind for other generations to finish. Reading by numbers is one way to recover some of the mystery behind the creative process.”
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information: